대상 독자
- 인덱스의 자료구조가 B Tree인 것은 알지만, 왜 B Tree를 사용하는지 상세한 원리를 알고 싶은 분
- B Tree 자료구조의 시간복잡도는 왜 O(logN)인지 알고 싶은 분
- 여러 Balanced Tree 중 왜 하필 B Tree를 선택했는지 답을 알고 싶은 분
들어가는 글
MySQL의 InnoDB 스토리지 엔진은 B+트리를 기반으로 인덱스를 구현한다.
DB 검색 효율과 속도 향상을 위해 인덱스가 사용된다는 점을 대부분의 개발자는 인지하고 있지만,
정확히 어떤 원리로 B+Tree(인덱스)가 데이터베이스의 검색 성능 향상을 이끌어내는지는 간과할 수 있다.
이 포스트에서는 MySQL의 InnoDB를 비롯한 여러 데이터베이스의 인덱스에서 왜 B+Tree를 선택했는지, B+Tree의 특징과 동작원리 중심으로 그 이유를 알아보려 한다.
왜 B Tree일까?
일반적인 Tree 자료구조는 Typical BST처럼 트리 형태로 데이터를 저장하여 데이터 탐색에 O(logN)의 시간복잡도를 갖는다.
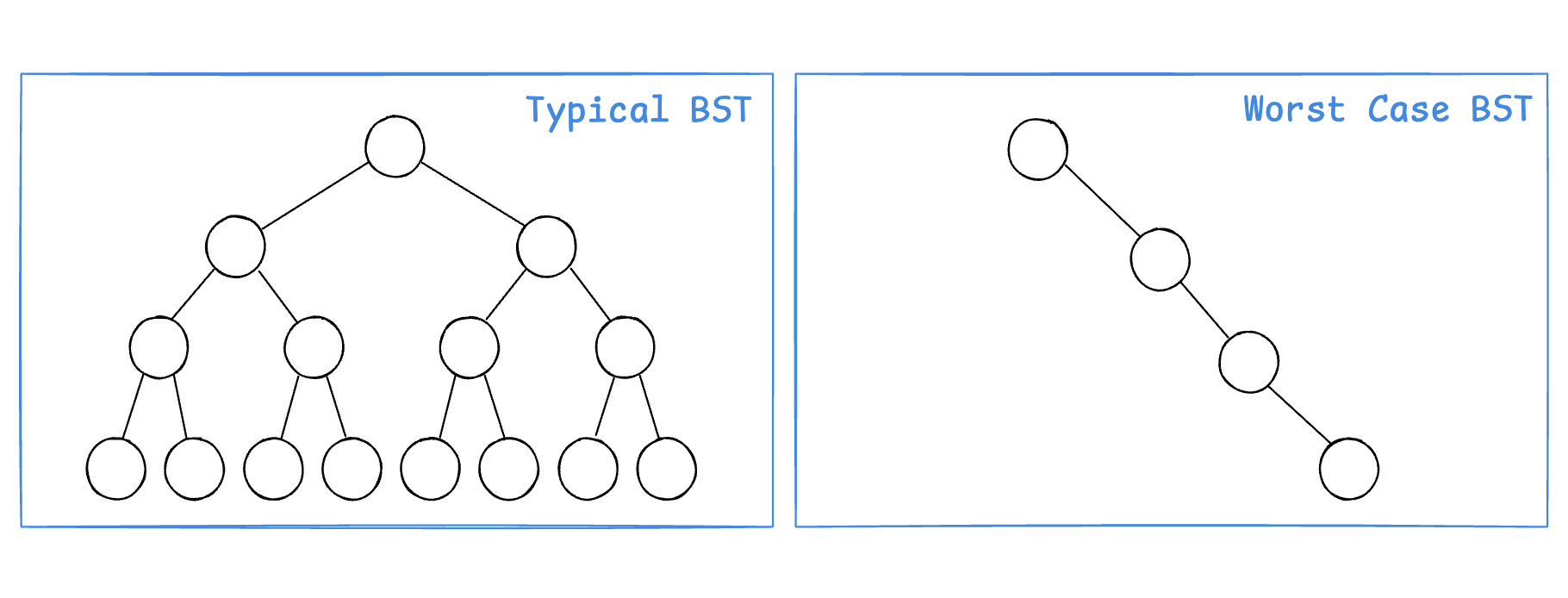
그러나 일반적이지 않은, 최악의 경우(worst-case)의 트리라면 어떨까?
트리가 데이터를 저장할 때 한쪽으로 쏠리는 경우엔 O(N) 시간 복잡도를 가지며 리스트와 별반 차이가 없어진다.
이렇듯 선형으로 데이터가 저장되는 최악의 경우를 방지하고자
인덱스의 자료구조는 균형 트리(Balanced Tree) 구조를 선택하여 트리의 형태를 유지하기로 했다.
Balanced Tree
밸런스 트리는 트리 노드가 한 방향으로 쏠리지 않도록
노드 삽입/삭제 시 특정 규칙에 맞게 전체 트리 구조를 재정렬하여 양쪽의 밸런스를 유지한다.
항상 양쪽 자식의 균형을 유지하면서 데이터 삽입/삭제가 이뤄져 밸런스 트리는 데이터 조회 시 O(logN)의 시간복잡도를 만족한다.
데이터가 추가/삭제 될 때 균형을 맞추는 리밸런싱이 수행되어 일반 트리보다 삽입/삭제 성능이 떨어지는 대신,
데이터 조회(탐색)의 성능을 높인 자료구조라 볼 수 있다. 대표적인 Balanced Tree는 Red-Black tree와 AVL Tree, B+Tree가 있다.
그럼 MySQL InnoDB는 왜 B+Tree를 인덱스의 자료구조로 선택하게 됐을까?
Red-Black Tree와 B+Tree 모두 Balanced Tree라는 점에서 유사하지만, 노드 당 가질 수 있는 키의 개수에서 결정적인 차이가 발생한다.
Red-Black Tree는 노드 당 하나의 키를 갖고 최대 2개의 자식과 연결되지만
B+Tree는 노드 당 하나 이상의 키를 가지며 그만큼 연결되는 자식 노드의 수도 늘어나게 된다.
정리하면 B+Tree는 노드 당 여러 개의 키를 가진다. 그것이 왜 인덱스로 선택된 중요한 이유인지 B+Tree의 구조를 차례로 살펴보며 이해해보자.
Red-Black Tree의 특징 요약
> 📌 Red-Black Tree 특징 > > - 높이 : O(log₂N) > - 노드 당 키 개수 : 1개 > - Disk I/O : 많음 (트리 높이만큼) > - 순차 접근 : 중위 순회 필요 > - 공간 활용 : 비효율적B+트리의 구조 (feat.키, 자식 노드)
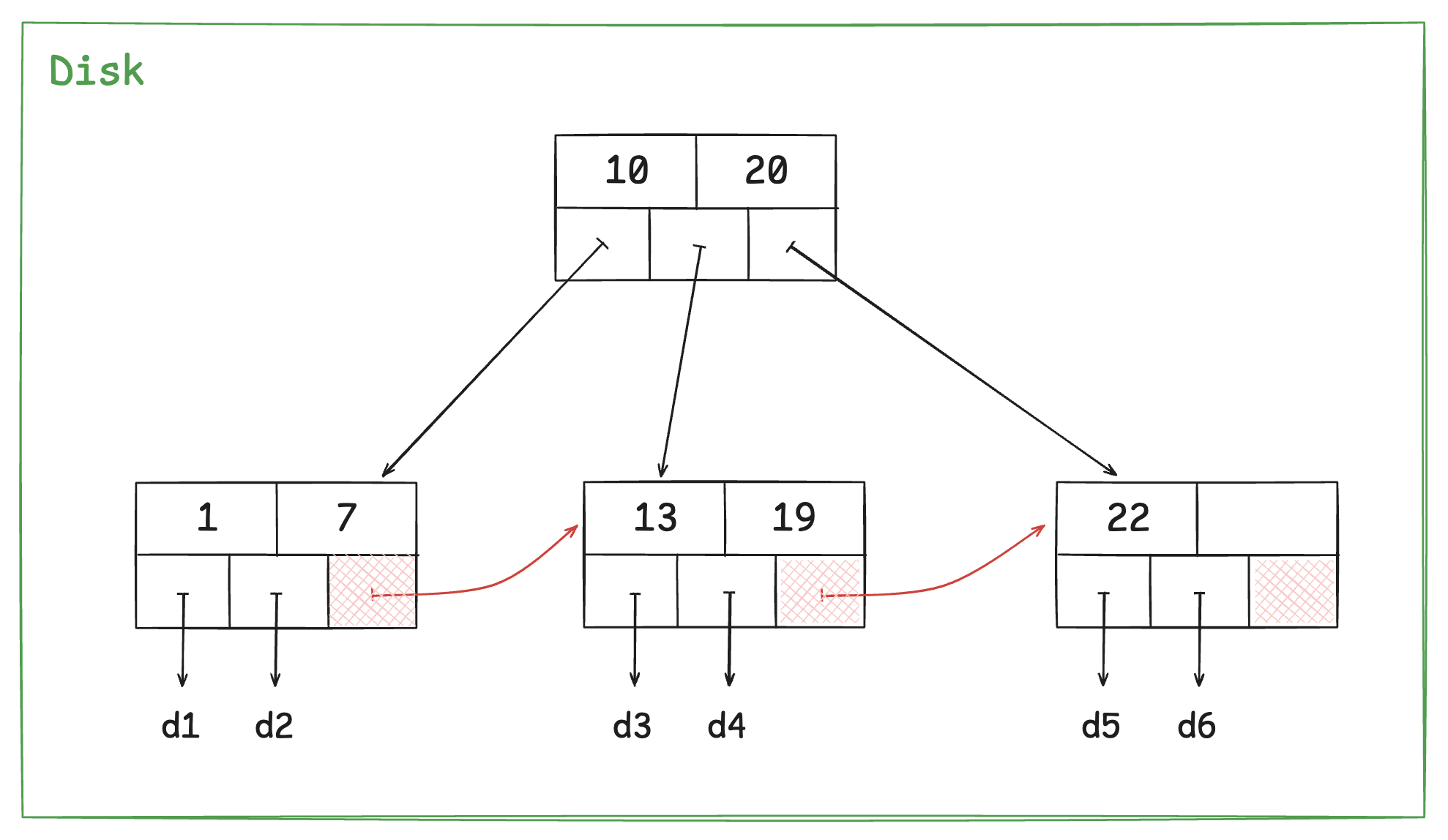
최대 2개의 자식 노드를 갖는 BST, Red-Black Tree와 달리 B+트리는 부모 노드에 한 개 이상의 키를 저장하여 두 개 이상의 자식 노드를 정렬된 상태로 관리한다. 이 때 부모 노드의 키는 오름차순으로 정렬되고, 정렬된 키 순서에 따라 저장할 수 있는 자식노드의 범위가 결정된다.
최대 M 개의 자식 노드를 가지는 B 트리를 M 차 B 트리라고 하며 구성은 아래와 같다.
M: 각 노드의 최대 자녀 노드 수M - 1: 각 노드의 최대 키 수M/2: 각 노드의 최소 자녀 노드 수M/2 - 1: 각 노드의 최소 키 수
B+트리는 전체적인 균형을 유지하도록 설계됐는데 이는 트리의 각 노드가 특정 키와 자식 노드 수 조건을 만족해야 함을 의미한다.
루트 노드: 최소 자식 노드 수: 2 (단, 트리가 비어 있거나 키가 하나뿐인 경우 제외).내부 노드: 모든 내부 노드는 최소⌈M/2⌉ 개의 자식 노드를 가져야 한다.리프 노드: 모든 리프 노드는 같은 깊이에 위치하여 트리의 균형을 유지한다.
B+Tree 구조에서 중요한 점은 모든 리프노드가 동일한 레벨에 위치하며, 링크드 리스트 형태로 서로 연결돼 있다는 점이다.
모든 리프 노드는 동일한 레벨에 위치하므로 특정 데이터를 찾을 때 루트 노드에서 리프 노드까지 도달하는 경로(높이) 역시 항상 동일하다.
즉 인덱싱 된 데이터는 모두 동일한 탐색 시간복잡도 O(logN)을 갖는다.
B+Tree의 노드는 각 키 값을 정렬된 채로 저장하며 이는 리프 노드에서도 동일하다.
즉 이웃 리프 노드와 링크드 리스트 형태로 연결된 모든 리프 노드는, 결국 정렬된 채로 이어졌다고 볼 수 있으므로
범위 탐색(Range Query) 및 순차 검색(Sequential Search)에 매우 효율적이다.
예를 들어 특정 값의 범위를 찾거나 정렬된 데이터를 순서대로 탐색할 때, 루트에서 시작해 범위의 시작점이 있는 리프 노드에 도달하면 링크드 리스트를 따라 필요한 값을 연속적으로 검색할 수 있다.
노드 방문과 Disk I/O
B+Tree는 데이터베이스라는 물리적인 Disk 저장공간에 위치하며, 각 노드를 방문할 때마다 Disk I/O(디스크 입출력)가 발생한다.
데이터 검색 시 처음 조회되는 노드, 즉 디스크 블록(노드 중 하나)을 메모리에 로드할 때 Disk I/O 발생하고
트리 depth를 따라 노드를 방문할 때마다 Disk I/O가 발생하는 셈이다.
매번 노드를 방문할 때마다 Disk I/O가 발생하면 조회 속도가 좋을 리 없지만,
B+Tree는 하나의 노드에 여러 키를 저장하여 트리 전체의 Depth를 낮게 유지하여 Disk I/O 횟수를 적게 유지할 수 있다.
InnoDB의 B+Tree는 최대 2~4 사이의 depth를 가지는 것으로 알려져 Disk I/O 역시 획기적으로 줄이는 장점이 있다.
또한 B+Tree는 각 노드가 1개 이상의 키를 가지고 있다는 점도 Disk I/O 관점에서 장점이 된다. BST 경우 자식 노드의 개수가 2개 이하로 각 노드에서 탐색 범위를 절반씩만 줄여나갈 수 있지만, B+트리는 여러 개의 키를 가지기 때문에 탐색 범위를 더 빠르게 좁힐 수 있어 루트 노드에서 리프노드까지 도달하는 거리도 더 짧다. 물리적 관점에서 더 적은 횟수의 Disk I/O로 데이터베이스에서 값을 찾을 수 있단 의미이기도 하다. 예를 들어 6차 B+트리의 경우, 각 노드의 자식 노드 개수가 3~6개인 반면 Red-Black Tree나 AVL Tree의 경우 자식 노드 개수가 최대 2밖에 되지 않는다. 10개의 데이터를 저장한다고 가정할 때, B+Tree는 Depth 1로 모든 데이터를 저장할 수 있지만, 다른 두 밸런스 트리의 Depth는 3이나 돼야 한다.
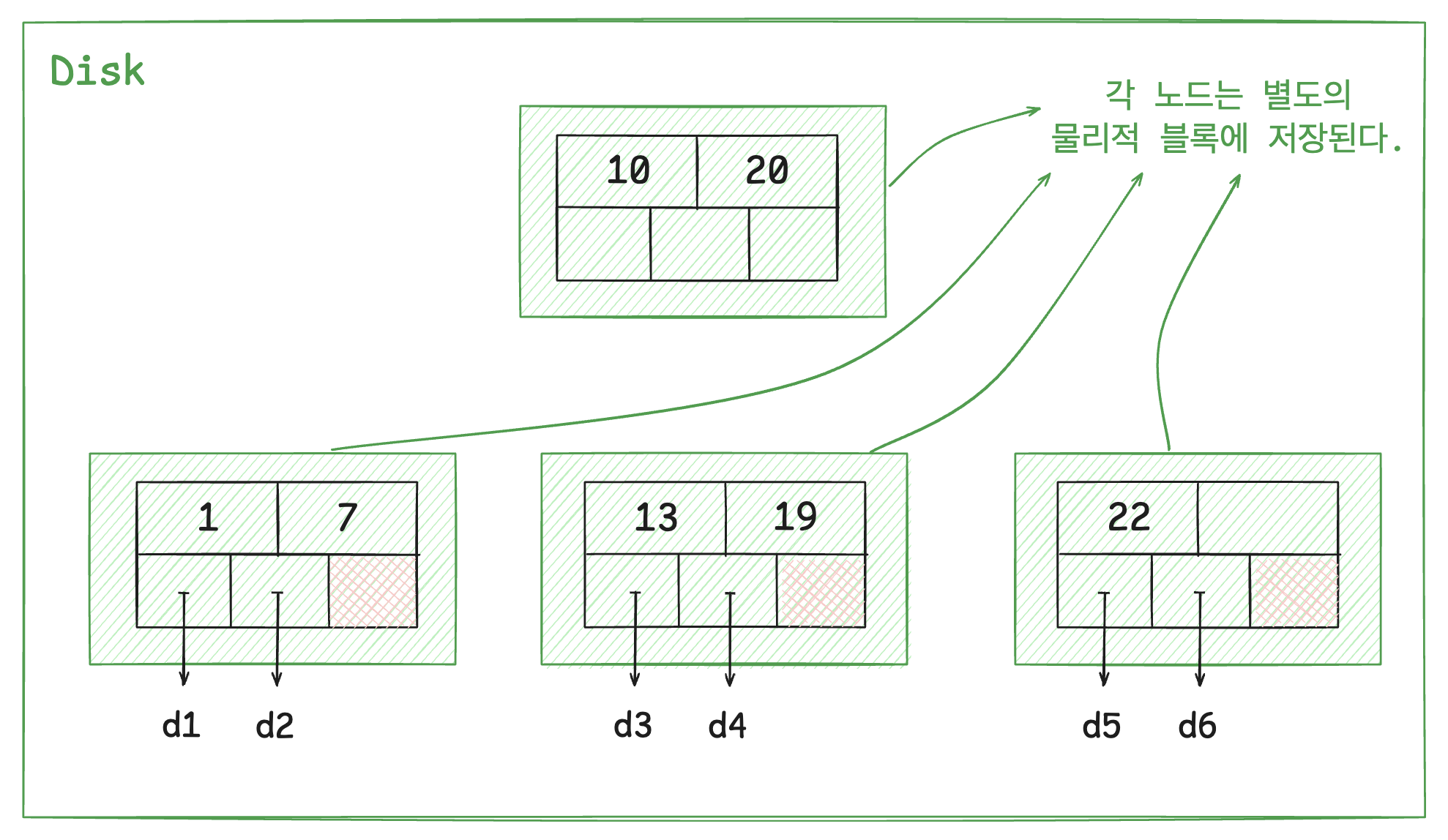
Q. 한 번의 Disk I/O로 여러 노드를 찾을 수 없는 이유
B+Tree에서 한 번의 Disk I/O로 여러 노드를 찾을 수 없는 이유는 B+Tree의 데이터 저장 방식과 디스크의 물리적 특성 때문이다.
디스크는
블록 단위로 데이터를 읽고 쓴다. 디스크는 고정 크기의 블록(예: 16KB) 단위로 데이터를 처리하는데, 한 번의 I/O는 특정 블록에 접근하여 해당 블록의 데이터를 메모리로 로드한다. 자식 노드는 물리적으로 다른 블록에 저장되므로 이를 탐색하려면 추가 I/O를 수행한다.B+Tree의 설계 목적 : B+Tree는 한 번에 한 노드씩 접근하며 필요한 경로만 따라가는 방식으로 설계되었다. 이 방식은 전체 트리를 탐색하지 않고도 필요한 데이터에 빠르게 접근할 수 있도록 최적화되어 있다.
이쯤 알아보는 시간복잡도가 O(logN)인 이유
앞서 B+Tree는 O(logN)의 시간복잡도를 가지기 때문에 일반적인 BST보다 빠르게 검색이 가능하다고 밝혔다. BST는 최악의 경우 선형구조로 데이터가 저장될 수 있어 O(N) 시간복잡도를 가질 수 있지만, B+Tree는 자체적으로 self-balancing 과정을 통해 시간복잡도를 O(logN)으로 유지할 수 있다.
그럼 왜 B+Tree는 O(logN)의 시간복잡도를 갖는지, 다소 수학적인 분석이 들어가지만 그 이유에 대해서도 알아보자.
우선 B+Tree의 구조적 특성을 다시 짚어보면,
최대 M개의 자식 노드를 가지는 B+Tree를 M차 B 트리, 각 노드는 최소 M/2에서 최대 M개의 키를 가진다.
📌 4차 B+트리(M=4)를 예로 들면, 각 노드는 최소 2개의 키를 가지므로 레벨별 최소 키 개수는 다음과 같이 증가한다:
레벨 1: 최소 2개의 키레벨 2: 최소 2 × 2 = 4개의 키레벨 3: 최소 4 × 2 = 8개의 키- ...
레벨 h: 최소 2h개의 키
이처럼 트리의 레벨(depth = h)이 증가할수록 최소 키의 개수는 2의 h승으로 증가한다.
위 내용을 그림으로 표현하면 아래와 같다.
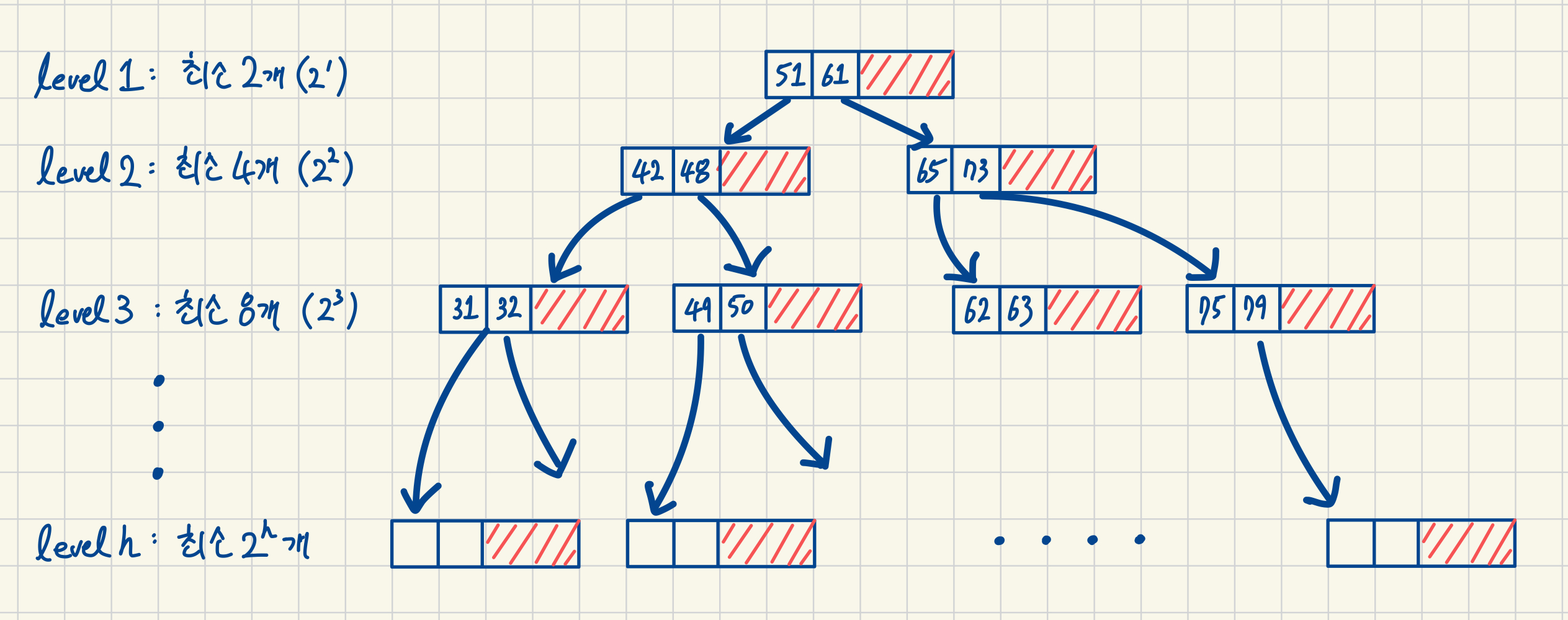
높이가 h인 트리에 N개의 키가 있으면 2h ≤ N 식이 성립한다. 왜냐하면 2h는 어디까지나 최소 키의 개수를 산정한 것이기 때문에 N은 2h 이상의 값을 가지게 된다. 이를 로그로 풀어내면 log₂N이 되므로 시간복잡도는 O(logN)이 되는 것이다.
🙋❓ 위 케이스는 M=4인 4차 B+Tree를 예시로 들었지만 만약 M=10인 B+Tree는 어떨까?
10차 B+Tree(M=10)의 경우, 각 노드는 최소 5개(M/2)의 키를 가져야 한다:
- 레벨 1: 최소 5개의 키
- 레벨 2: 최소 5 × 5 = 25개의 키
- 레벨 3: 최소 25 × 5 = 125개의 키
- ...
- 레벨 h: 최소 5h개의 키
이는 앞서 본 4차 B+Tree와 같은 원리지만 최소 키 개수가 2가 아닌 5를 기준으로 증가한다.
따라서 N개의 키가 있을 때:
markdown4차 B+Tree: N ≥ 2^h → h ≤ log₂N 10차 B+Tree: N ≥ 5^h → h ≤ log₅N
동일한 개수의 데이터를 저장한다면, 10차 B+Tree 가 4차 B+Tree 보다 더 적은 레벨로 데이터를 저장할 수 있고, 이는 곧 Disk I/O 횟수를 줄여 데이터 조회 성능을 높이는 효과로 이어진다.
예를 들어:
markdownN = 1,000,000 일 때 4차 B+Tree : h ≤ log₂(1,000,000) ≈ 20 ➡️ (level 이 20인 Tree) 10차 B+Tree : h ≤ log₅(1,000,000) ≈ 9 ➡️ (level 이 9인 Tree)
이것이 실제 데이터베이스에서 더 큰 M값을 선호하는 이유 중 하나다!
M값이 너무 크면 한 노드의 크기 역시 커지므로 메모리 관리에 부담 될 수 있지만,
적정 크기의 M 은 곧 트리 레벨을 낮게 유지할 수 있는 요인이 되므로 적절한 균형점을 찾는 것이 중요하다.
실제로 MySQL 의 B+Tree 는 실제 프로덕션 환경에서 보통 2~4 정도의 높이를 가진다.
하나의 노드에 평균적으로 100~200 의 차수를 가지는 셈인데, 예를 들어 키가 Int 타입이라면 4byte 크기를 가지므로 차수(M)는 133 정도가 된다.
마무리
B+Tree 의 전체적인 구조와 시간복잡도, 동작원리를 살펴보면서 왜 인덱스의 자료구조로 선택됐는지 학습했다.
요약하자면 MySQL 의 인덱스는 조회 성능 향상을 위해 사용되며, 인덱스는 B+Tree를 기반으로 구현됐다.
B+Tree 는 Self-Balanced Tree 로 삽입/삭제 시 스스로 균형을 맞추는 특징을 가진다.
스스로 균형을 맞추기 때문에 트리의 Depth 가 무한정 늘어나지 않아 항상 일관된 시간복잡도를 가질 수 있고, 이는 Disk I/O 측면에서도 이점을 지닌다.
여타 다른 Self-Balanced Tree 와 결정적인 차이는 노드 당 가질 수 있는 키의 개수인데,
노드 당 여러 키를 가지는 B+Tree 는 트리의 높이 감소, Disk I/O 효율, 범위 검색 최적화 등 다양한 측면에서 성능과 효율을 제공한다.
🙏🏻 ref